Riassumi questo articolo di notizie con l'intelligenza artificiale:
Introduzione
Con l’accelerazione delle iniziative di sostituzione di VMware da parte delle organizzazioni, emerge costantemente una domanda: le mie applicazioni database e i carichi di lavoro ad alta intensità di I/O funzioneranno altrettanto bene - o meglio - sulla nuova piattaforma di virtualizzazione? Per anni, VMware vSphere è stato lo standard di riferimento per l’esecuzione di applicazioni mission-critical, e qualsiasi migrazione solleva naturalmente preoccupazioni sulla coerenza delle prestazioni, sui picchi di latenza e sull’efficienza nell’uso delle risorse.
La Sangfor Virtualization (HCI) non è semplicemente una sostituta “plug-and-play”. È progettata per soddisfare i requisiti prestazionali più esigenti dei sistemi aziendali core. Grazie a un’ottimizzazione profonda dell’architettura sottostante, in particolare per quanto riguarda la pianificazione NUMA (Non-Uniform Memory Access) e l’espansione della capacità di memoria, la Sangfor Virtualization garantisce che database, cache in memoria e altri carichi di lavoro sensibili all’I/O non solo mantengano le prestazioni precedenti, ma spesso le superino.
In questo articolo analizzeremo due tecnologie fondamentali che rendono possibile tutto ciò: Adaptive NUMA Scheduling e Memory Tiering. Basandoci su dati di test validati e su considerazioni architetturali, vedremo come queste funzionalità affrontano i principali colli di bottiglia prestazionali negli ambienti server moderni.
Parte 1: Ridurre la latenza di accesso alla memoria con l’Adaptive NUMA Scheduling
La sfida NUMA negli ambienti virtualizzati
I server aziendali moderni si basano sull’architettura NUMA per superare i limiti del multiprocessing simmetrico (SMP) tradizionale. In un sistema NUMA, i core del processore e la memoria sono suddivisi in nodi. Ogni nodo dispone della propria memoria locale: l’accesso a questa è veloce, mentre l’accesso alla memoria di un nodo remoto comporta una latenza significativamente maggiore. Gli accessi alla memoria locale richiedono circa 70–90 ns; quelli remoti sono generalmente da 1,5 a 2 volte più lenti e possono peggiorare ulteriormente in presenza di contesa.
In un ambiente virtualizzato, ogni macchina virtuale è rappresentata da un insieme di thread vCPU. Se questi thread vengono distribuiti su diversi nodi NUMA o migrano tra nodi, la VM sperimenterà accessi a memoria remota, con conseguente latenza imprevedibile e riduzione del throughput. Questo è particolarmente critico per sistemi database come Oracle, DM8 e PostgreSQL, nonché per datastore in memoria come Redis.
L’approccio di VMware vSphere
VMware vSphere (dalla versione 6.0 in poi) include uno scheduler NUMA automatico che gestisce efficacemente la maggior parte dei carichi di lavoro generici. Offre funzionalità come l’esposizione vNUMA e il bilanciamento del carico tra nodi. Tuttavia, per carichi altamente specializzati e intensivi in I/O, gli amministratori potrebbero comunque dover ottimizzare manualmente l’affinità della CPU o modificare parametri avanzati per ottenere prestazioni ottimali.
Adaptive NUMA Scheduling di Sangfor Virtualization
La Sangfor Virtualization adotta un approccio radicalmente diverso. Invece di basarsi su interventi manuali, implementa un motore di scheduling NUMA completamente adattivo, che opera in modo automatico e dinamico. Lo scheduler analizza continuamente il numero di vCPU di ciascuna VM e il carico in tempo reale dei nodi NUMA fisici, prendendo decisioni di posizionamento ottimali. Come illustrato, il sistema seleziona automaticamente il nodo NUMA più appropriato per ogni macchina virtuale.
- Quando il numero di vCPU di una VM è inferiore al numero di core di un nodo NUMA, la VM viene assegnata a un singolo nodo.
- Quando il numero di vCPU supera i core disponibili su un nodo, la VM viene distribuita su più nodi NUMA, e la topologia vNUMA viene esposta al sistema operativo guest, permettendo decisioni interne più efficienti.
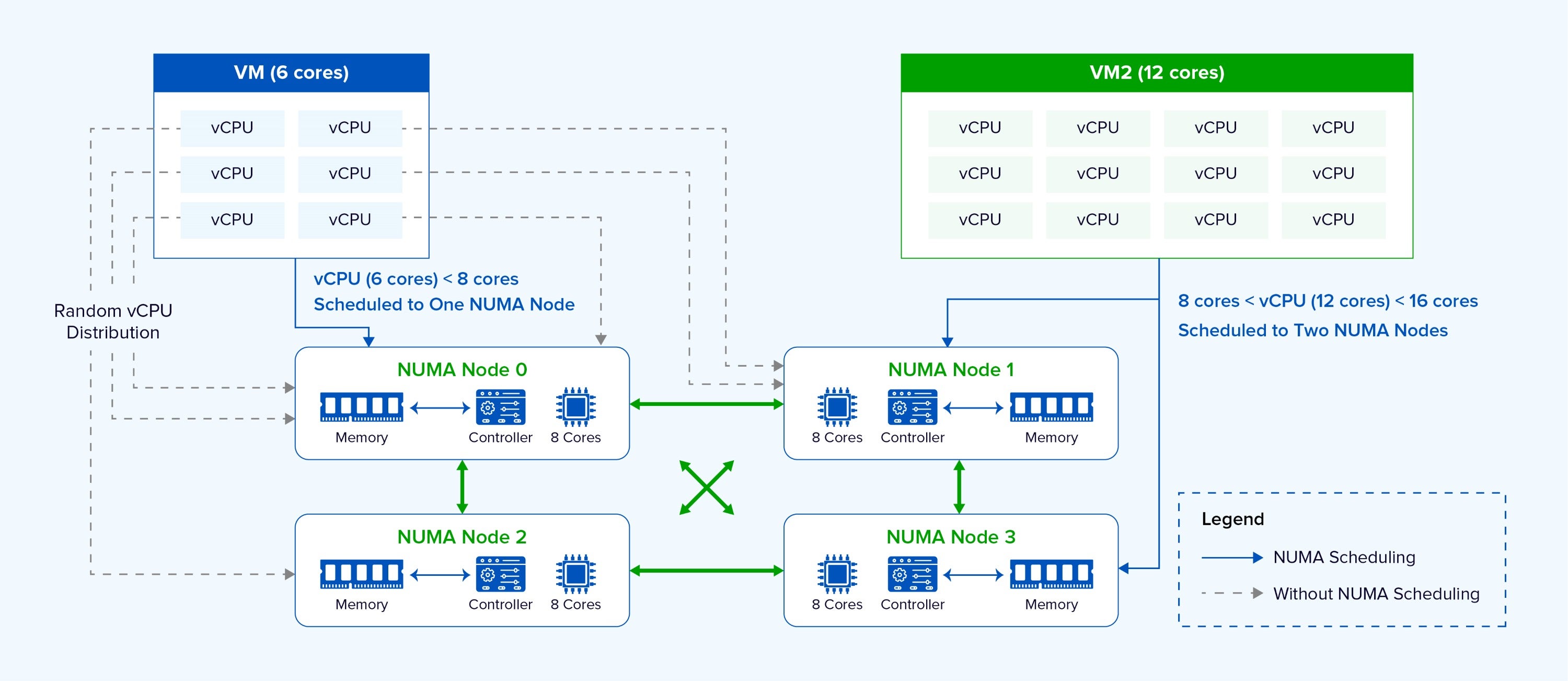
- Consolidamento delle vCPU: Quando il numero di vCPU di una VM è inferiore o uguale al numero di core di un singolo nodo NUMA fisico, Sangfor Virtualization colloca tutte le vCPU e la memoria nello stesso nodo. Questo garantisce accesso alla memoria locale al 100%, eliminando la latenza tra nodi.
- Distribuzione intelligente per VM di grandi dimensioni: Per le VM con più vCPU di quelle gestibili da un singolo nodo, lo scheduler le distribuisce su più nodi NUMA. Fondamentale è l’esposizione della topologia vNUMA al sistema operativo guest, che può così ottimizzare ulteriormente la località della memoria.
- Bilanciamento del carico tra nodi: Lo scheduler monitora costantemente il carico dei nodi NUMA e può migrare le VM tra nodi per evitare congestioni. Inoltre, identifica le VM “critiche” (ad esempio quelle che eseguono database fondamentali) e ne prioritizza il posizionamento su nodi meno congestionati, garantendo prestazioni stabili.
Oltre le vCPU: affinità NUMA per storage e rete
Ciò che distingue la Sangfor Virtualization è che le sue ottimizzazioni NUMA vanno ben oltre la semplice pianificazione della CPU. Un intero percorso I/O, dalla vCPU, al processo QEMU, al servizio di storage aSAN, fino al processo di forwarding dei dati di rete, può essere associato in modo intelligente allo stesso nodo NUMA. Questo approccio olistico elimina gli accessi alla memoria remota lungo tutto lo stack I/O, riducendo drasticamente l’overhead di elaborazione.
In combinazione con le huge pages, questa ottimizzazione offre benefici diretti alle applicazioni database e a quelle ad alta intensità di storage. Ad esempio, quando un database esegue un’operazione di scrittura, l’intero flusso di lavoro rimane all’interno dello stesso dominio NUMA, riducendo al minimo la latenza e massimizzando il throughput.
Nota: l’ottimizzazione dell’affinità NUMA si applica all’interno di ciascun singolo host. L’accesso allo storage tra host diversi in configurazioni distribuite (come aSAN) comporta comunque latenza di rete, come previsto in qualsiasi architettura distribuita.
Validazione delle prestazioni
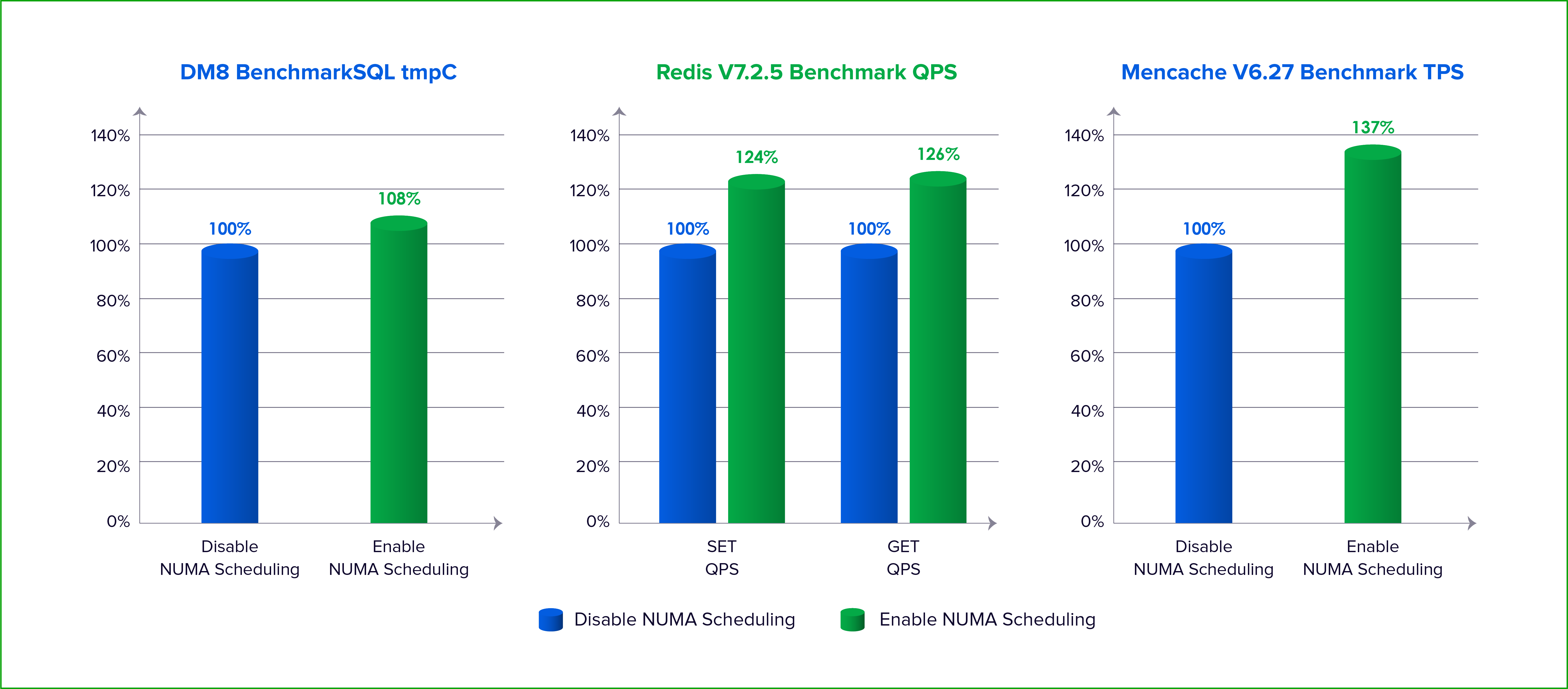
L’efficacia di queste ottimizzazioni è stata confermata tramite test rigorosi. In un benchmark condotto con DM8 (un importante database domestico) e lo strumento standard BenchmarkSQL (modello TPC-C), l’attivazione della pianificazione NUMA della Sangfor Virtualization ha portato a un aumento significativo del valore tpmC rispetto a una configurazione con NUMA disattivato.
Allo stesso modo, nei test su Redis utilizzando redis-benchmark per operazioni SET/GET, le query al secondo (QPS) sono migliorate sensibilmente con la pianificazione NUMA attiva. Anche i test su Memcache con memaslap hanno mostrato un incremento delle transazioni al secondo (TPS).
Questi risultati dimostrano che, per i carichi di lavoro sensibili all’accesso alla memoria (ovvero proprio quelli più penalizzati da una configurazione NUMA non ottimale), la Sangfor Virtualization è in grado di offrire miglioramenti prestazionali concreti.
Parte 2: Superare i limiti della capacità di memoria con il Memory Tiering
Il dilemma del costo della memoria
Per database e applicazioni ad alta intensità di I/O, la capacità di memoria è spesso la risorsa più critica. Pool di memoria più ampi consentono cache buffer più grandi (come la SGA di Oracle), una maggiore elaborazione dei dati in memoria e un incremento della concorrenza. Tuttavia, i prezzi della DRAM restano volatili e i vincoli nella supply chain hardware possono rendere gli upgrade di memoria su larga scala proibitivamente costosi.
Le tecniche tradizionali utilizzate in piattaforme come VMware vSphere, tra cui compressione della memoria, transparent page sharing e memory overcommit, migliorano l’utilizzo ma presentano limiti intrinseci. Non aumentano realmente la quantità di memoria disponibile, ma rendono semplicemente più efficiente quella esistente. Quando i carichi di lavoro richiedono più memoria attiva di quella fisicamente disponibile, le prestazioni inevitabilmente peggiorano.
Come funziona il Memory Tiering di Sangfor Virtualization
La Sangfor Virtualization introduce un cambio di paradigma attraverso il Memory Tiering. Questa tecnologia crea un pool di memoria unificato combinando DRAM ad alta velocità con SSD NVMe ad alte prestazioni. L’idea centrale è utilizzare gli SSD NVMe come estensione della memoria di sistema, raddoppiando di fatto la capacità disponibile senza aggiungere DRAM.
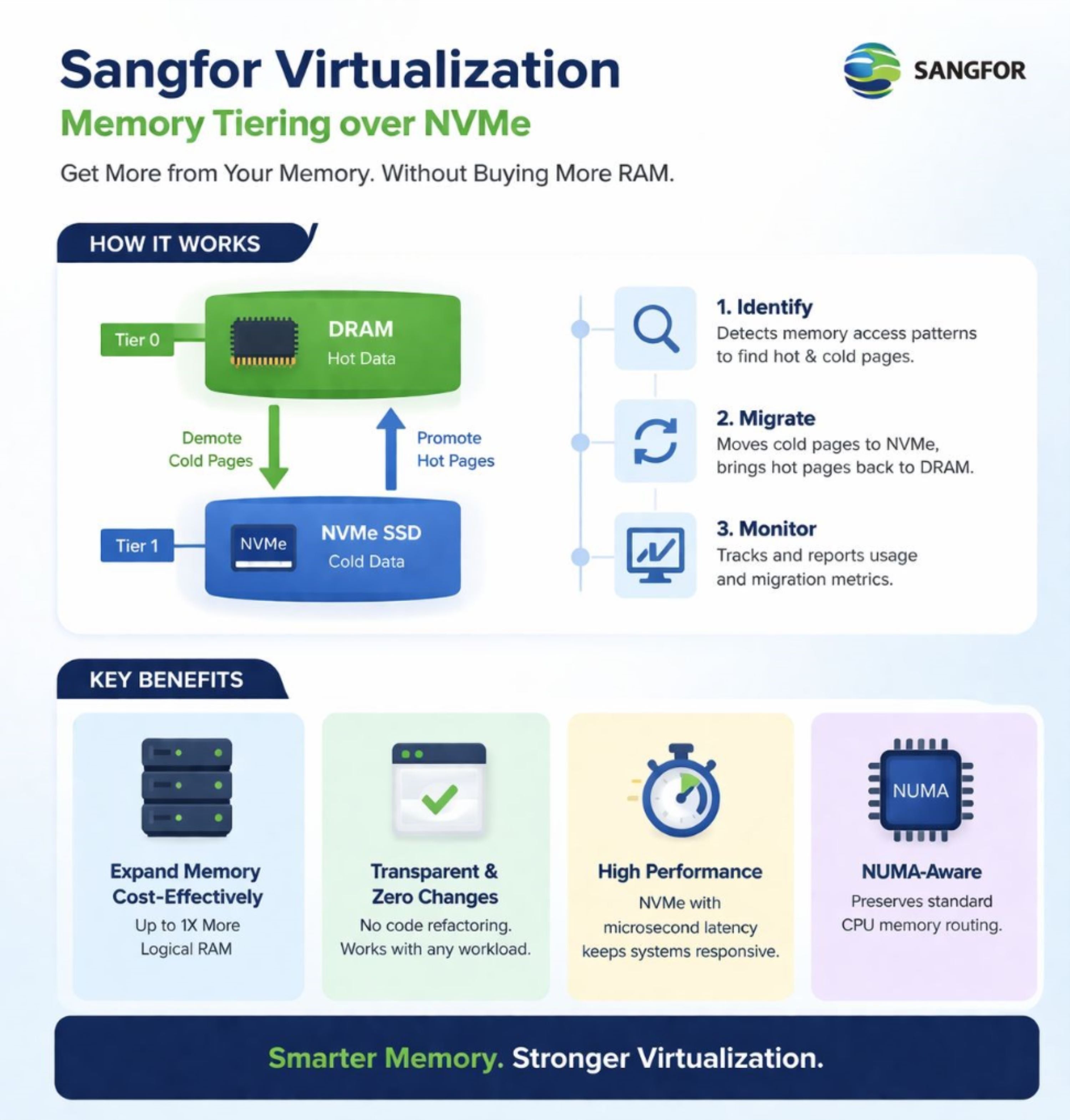
Il punto chiave è il posizionamento intelligente dei dati. Grazie a un meccanismo leggero di partizionamento dinamico delle regioni e campionamento sparso casuale, Sangfor Virtualization monitora continuamente le pagine di memoria per distinguere tra dati “caldi” (accessi frequenti) e “freddi” (accessi rari).
- Dati caldi - come indici di database attivi, log di transazioni critici o tabelle frequentemente interrogate - restano nel livello DRAM (Tier 0) per garantire accessi a bassa latenza.
- Dati freddi - come record storici, pagine legate ai backup o memoria inattiva delle applicazioni - vengono spostati automaticamente nel livello NVMe (Tier 1). Questa migrazione avviene in modo trasparente, senza coinvolgere il sistema operativo guest o le applicazioni.
Flusso di accesso della CPU e controllo delle prestazioni
Quando una CPU richiede un indirizzo di memoria, il sistema verifica prima il livello DRAM. Se la pagina è presente (hot hit), l’accesso è immediato. In caso contrario (cold miss), viene attivato un page fault trasparente: la pagina richiesta viene rapidamente riportata dall’NVMe alla DRAM e l’accesso della CPU viene completato. Dal punto di vista dell’applicazione, il processo è indistinguibile da una normale operazione di memoria.
È importante sottolineare che il livello NVMe viene trattato come memoria e non come spazio di swap. Il controller NVMe sfrutta la banda PCIe per trasferire dati con un intervento minimo della CPU. Con le moderne unità NVMe PCIe 4.0/5.0, che offrono latenze nell’ordine di 10–100 µs e bandwidth fino a 7 GB/s, l’overhead legato al recupero delle pagine “fredde” rimane estremamente contenuto.

Nei test reali su database Oracle, l’attivazione del memory tiering ha permesso a un server con 128 GB di DRAM fisica di supportare efficacemente carichi di lavoro che normalmente richiederebbero 256 GB. Il valore TPM (transazioni al minuto) è diminuito solo di circa il 10%, un compromesso modesto rispetto al raddoppio della capacità di memoria utilizzabile.
Flessibilità di implementazione e best practice
Non tutti i carichi di lavoro sono ideali per il memory tiering. Questa tecnologia è particolarmente adatta a scenari con una chiara distinzione tra dati “caldi” e “freddi”, come:
- Virtualizzazione desktop (VDI)
- Ambienti di sviluppo e test
- Servizi di caching non critici
- Cluster di microservizi con carichi moderati
Per esigenze di latenza ultra-bassa, il memory tiering può essere disattivato selettivamente per singola VM, ad esempio in:
- Sistemi di trading ad alta frequenza
- Database OLTP sensibili alla latenza con pattern di accesso uniformi
- Analisi in tempo reale con requisiti SLA stringenti
Sangfor raccomanda un rapporto DRAM/memory tiering pari a 1:1 per ottenere un equilibrio ottimale, raddoppiando la memoria effettiva con un impatto minimo sulle prestazioni.
Conclusione
La migrazione da VMware vSphere a Sangfor Virtualization non è semplicemente un passaggio laterale, ma un’opportunità per riprogettare il layer di virtualizzazione in ottica di maggiore efficienza e prestazioni. Per i carichi di lavoro database e ad alta intensità di I/O, le due tecnologie analizzate (Adaptive NUMA Scheduling e Memory Tiering) affrontano direttamente i principali vincoli delle infrastrutture moderne: la latenza di accesso alla memoria e la capacità disponibile.
L’Adaptive NUMA Scheduling garantisce che database, cache in memoria e middleware operino con accessi prevedibili e a bassa latenza alla memoria locale, adattandosi dinamicamente ai carichi senza necessità di interventi manuali. Il Memory Tiering, invece, offre un approccio pratico per scalare la capacità di memoria senza i costi elevati della DRAM, permettendo di consolidare più workload per server mantenendo prestazioni accettabili.
Grazie a queste innovazioni, laSangfor Virtualization offre una piattaforma che non solo eguaglia le prestazioni di VMware vSphere, ma spesso le supera, soprattutto negli scenari più esigenti tipici dei sistemi core aziendali. Durante il percorso di replacement di VMware, puoi quindi affrontare la transizione con la certezza che le applicazioni più critiche continueranno a operare in modo affidabile.
Se la tua organizzazione sta affrontando sfide simili, ti invitiamo a contattarci: siamo pronti a collaborare per un’analisi condivisa e sviluppare un piano di transizione su misura, perfettamente allineato al tuo ambiente.
