Summarize with AI:
Over the past two years, enterprise memory planning has quietly become one of the hardest problems in infrastructure design. The explosion of AI workloads and the rapid shift of semiconductor capacity toward High Bandwidth Memory (HBM) have driven server DRAM prices up by more than 170% year-over-year, with industry analysts warning that tight supply and elevated pricing may persist through at least 2027.
Yet in real-world production environments, memory utilization tells a different story. In virtualized and cloud-native platforms, applications such as JVM-based services, middleware platforms, big data and machine learning tend to reserve large memory spaces upfront, while only a portion of that memory is actively accessed at any given moment. The remaining pages stay idle for long periods, consuming expensive DRAM capacity without directly contributing to performance.
This gap between allocated memory and actively used memory is where a new optimization approach emerges.
Memory tiering is built on a simple but powerful observation: not all memory pages are equal. If frequently accessed “hot” data can stay on high-speed DRAM, while infrequently accessed “cold” data is transparently placed on a lower-cost, high-performance medium, overall memory capacity can be significantly expanded without proportionally increasing hardware cost.
However, this idea immediately raises critical questions for enterprise users:
- Can memory really be extended beyond physical DRAM without destabilizing performance?
- How does the system identify hot and cold memory accurately, without introducing high CPU overhead?
- When cold data is accessed again, how quickly can it return to high-speed memory and will applications notice?
These concerns are valid. Memory sits on the critical path of application performance, and any optimization at this layer must be both precise and predictable.
In this article, we take a practical and technical look inside Sangfor’s Memory Tiering Technology. We will explain why memory can be safely tiered, how DRAM and NVMe collaborate at the system level, and what design principles ensure that performance impact remains tightly controlled. Just as importantly, we will outline the scenarios where memory tiering brings clear value and where it should be used with caution.
Our goal is not to oversell a concept, but to provide a transparent framework that helps IT architects and decision-makers determine whether memory tiering is the right fit for their environments.
Why Can Memory Be "Tiered"?
In the realm of enterprise memory optimization, traditional solutions such as memory ballooning, transparent page sharing, memory compression, and memory overcommitment, can all improve physical memory utilization and alleviate pressure to some extent. However, this improvement is limited. As business scales continue to grow, new technological approaches are required to expand the system's available memory capacity.
In cloud-native and virtualized environments, applications (like JVMs, caching services, and middleware) typically reserve a large amount of memory space. However, the truly "active" memory that is frequently read and written only accounts for about 50%, while the rest remains in a low-access, "cold" state.
Based on this core characteristic, the memory tiering solution was born. By dividing memory data into a hot data tier and a cold data tier based on access frequency, it builds a unified memory resource pool using physical DRAM and high-performance NVMe SSDs. Relying on intelligent scheduling algorithms to dynamically route hot and cold data, we can break through physical memory limits without compromising core business performance.
How Do DRAM and NVMe Collaborate Intelligently?
Sangfor's Memory Tiering solution adopts a core architecture of a "Multi-Tier Memory Pool + Intelligent Scheduling Engine" to achieve highly efficient collaboration between DRAM and NVMe SSDs. This enables hierarchical memory management and dynamic scheduling with extremely low system overhead.
Multi-Tier Memory Pool Architecture Design
- Tier 0 (Hot Data Tier): High-speed DRAM handles high-frequency, latency-sensitive "hot" data, serving as the core guarantee for business performance.
- Tier 1 (Cold Data Tier): High-performance NVMe acts as a memory expansion layer, carrying low-frequency "cold" data to achieve elastic expansion of memory capacity.
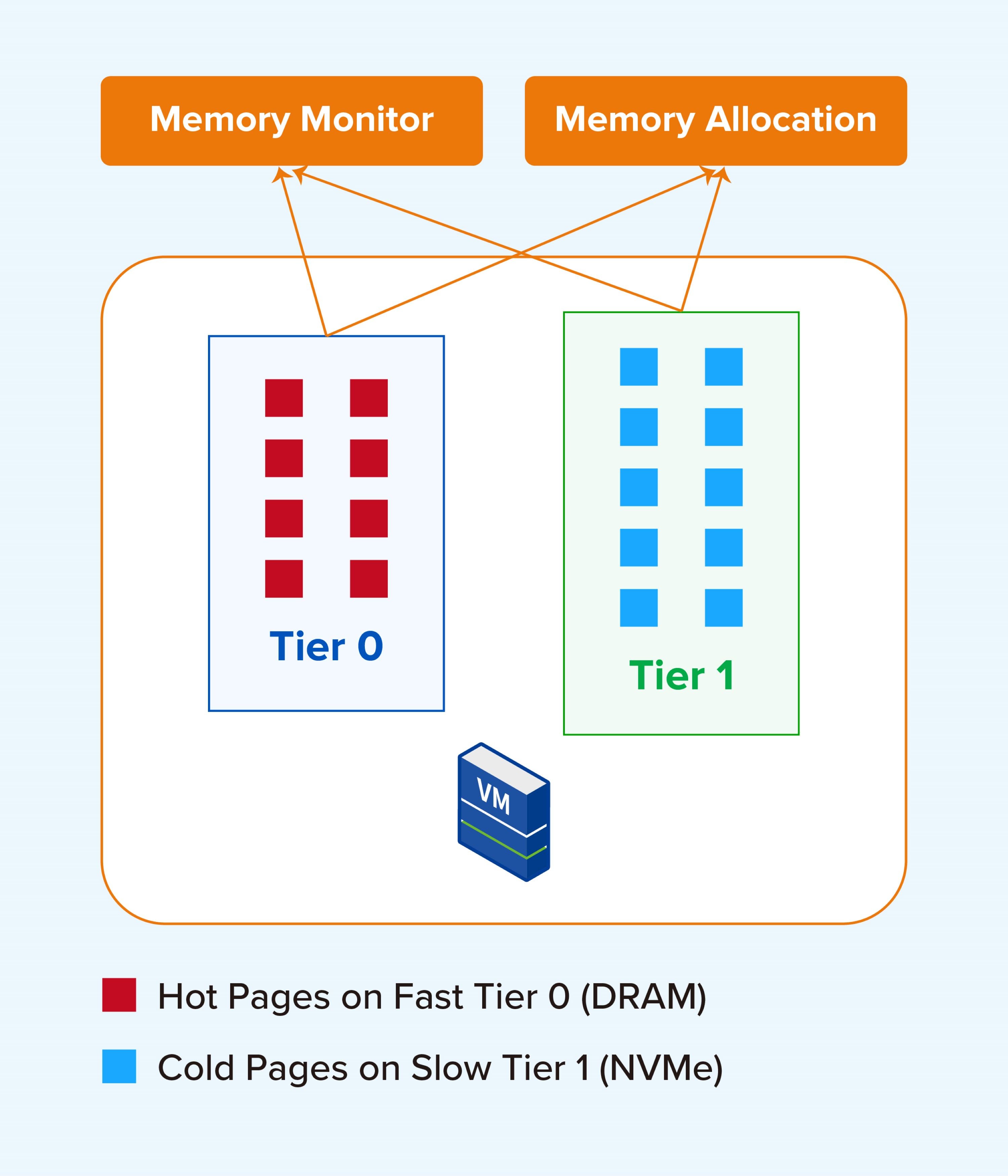
Multi-Tier Memory Pool Architecture Design
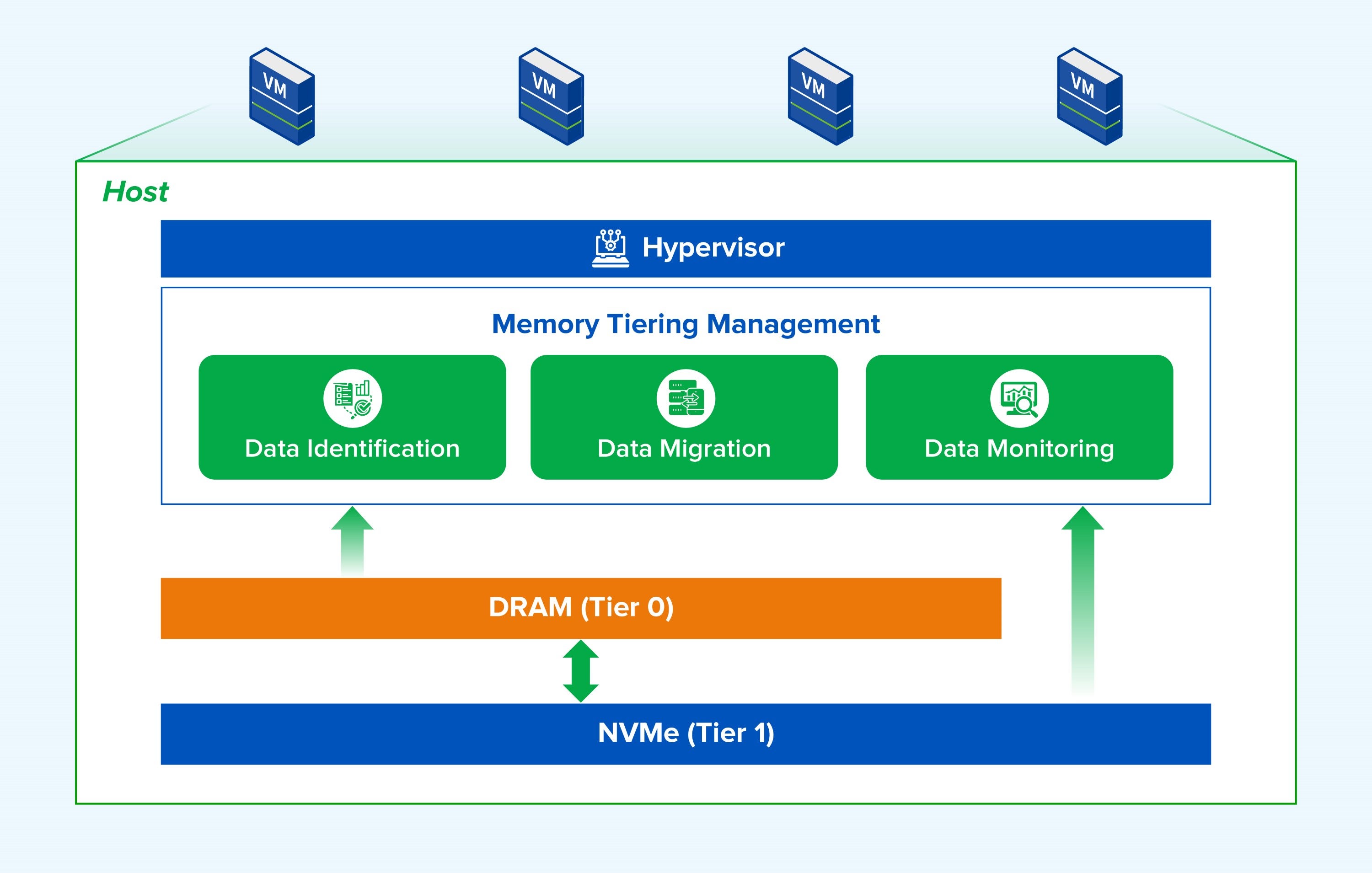
Intelligent Scheduling Engine
The intelligent scheduling engine is the core of the memory tiering solution. By utilizing "dynamic region partitioning + random sparse sampling" technology, it assesses the global distribution of hot and cold memory with minimal system overhead, enabling accurate identification and dynamic scheduling.
The Path of CPU Access Memory
It consists of three core capabilities:
- Accurate Hot/Cold Identification (Precise Targeting): Through continuous heat detection, it maps out the actual active working set of the business in real-time. It accurately distinguishes which hot data must remain in high-speed DRAM and which cold pages can be safely demoted.
- Automated Memory Migration (Fast Moving): Automatically executes "cold data demotion" and "hot data promotion." This frees up DRAM space for core applications while ensuring re-activated data instantly returns to the hot tier to guarantee seamless access performance.
- Full-Link Observability (Clear Visibility): Continuously monitors memory heat distribution, page migration behavior, and cold tier access status to form a comprehensive observability capability. This monitoring data helps IT operations identify potential performance risks and provides a solid basis for policy optimization and capacity planning.
Hot and Cold Data Flow Between DRAM and NVMe
- DRAM → NVMe (Cold Page Demotion): Once the system identifies a low-access cold page, it is added to the cold page migration candidate queue. The system allocates NVMe storage space, writes the page data from DRAM to the NVMe SSD, and synchronously updates the memory mapping. Once migrated, the corresponding DRAM space is freed, ensuring high-speed memory is prioritized for active data.
- NVMe → DRAM (Hot Page Promotion): When an application re-accesses a page that was previously demoted to the NVMe cold tier, the system captures the request in real-time and triggers the promotion process. It reads the target page data from NVMe back into DRAM and updates the memory mapping synchronously, allowing the re-activated data to enter the high-speed memory tier and restore normal performance.

Data Migration Mechanisms
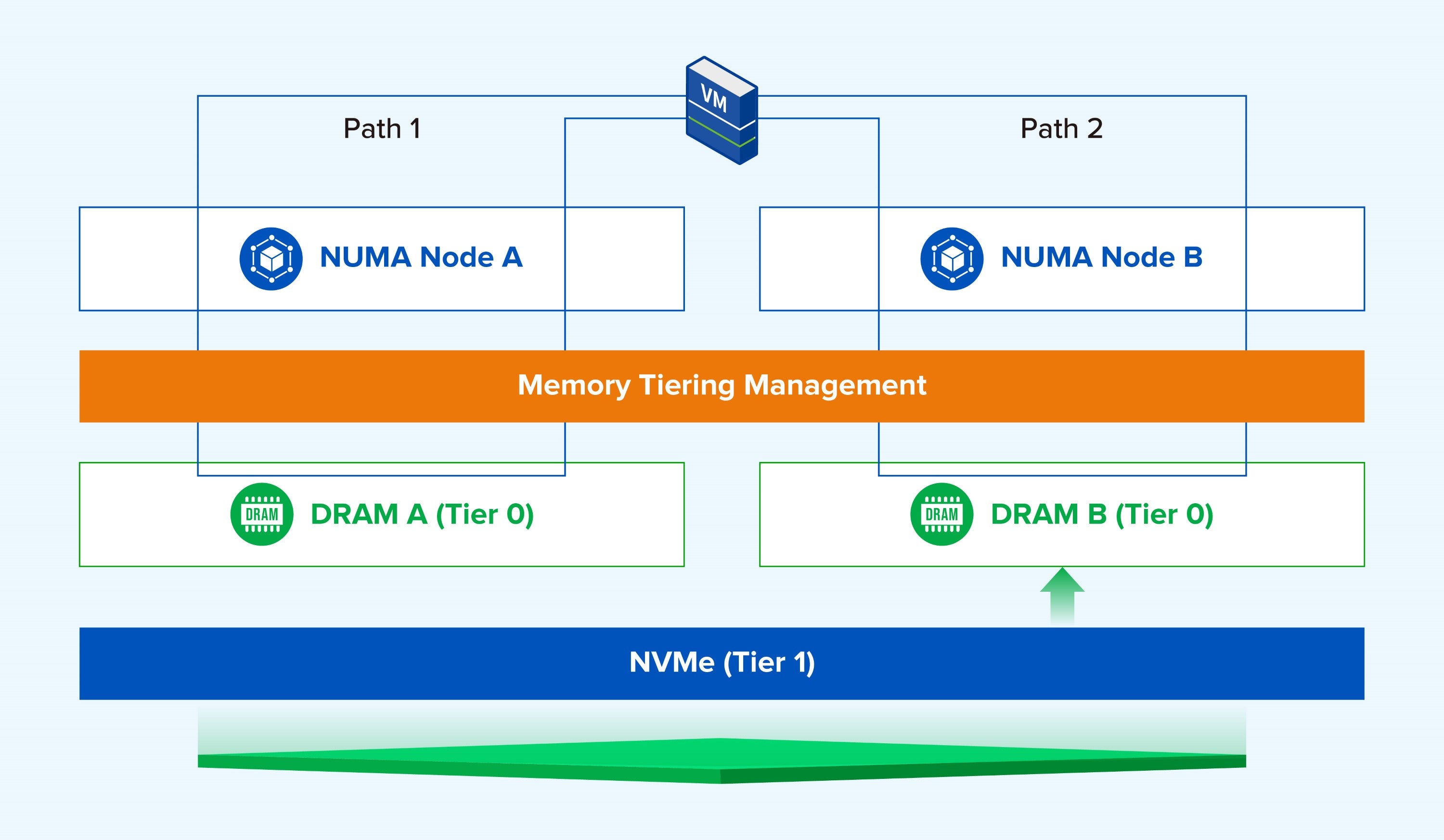
How Does the CPU Access Tiered Memory? Minimizing Performance Loss
The technical challenge of memory tiering lies in how to quickly identify data, schedule pages, and allow the CPU to rapidly access memory once it is tiered.
In this architecture, the NVMe device is not used as traditional storage, but as a Cold Memory Tier beneath the DRAM. Therefore, all CPU memory access operations are ultimately completed via DRAM. The access paths are divided into two types:
- Path 1: Hot Page Hit: CPU initiates access → Local/Remote DRAM → Returns data.
- Path 2: Cold Page Miss: CPU initiates access → Target page is not in the DRAM hot tier → System retrieves the page from NVMe back to DRAM → CPU accesses the page.
Memory Tiering Architecture
Since the server CPU does not directly access NVMe, how do we keep the performance impact minimal? To address concerns about post-tiering performance, the system ensures business stability through the following mechanisms:
- Unified Address Space & Transparent Access: This is entirely transparent to applications. When accessing a hot page in DRAM, it's a direct hit with zero extra overhead. When accessing a cold page in NVMe, it triggers a page fault interrupt; the OS kernel quickly pulls the data from NVMe back to DRAM, allowing CPU access. The CPU operates without knowing whether the data was in DRAM or NVMe—the kernel handles everything.
- Intelligent Scheduling & Dynamic Region Adjustment: The system dynamically adjusts the region structure based on monitoring results to balance accuracy and system overhead. When adjacent regions have similar access patterns, they automatically merge to reduce monitoring objects. When clear hot spots are detected within a region, it splits for finer-grained identification. This adaptive mechanism keeps monitoring granularity optimal.
- Low Latency NVMe Minimizes Transfer Overhead: The NVMe controller reads and writes to DRAM directly via PCIe without CPU intervention, consuming very few CPU interrupt resources. NVMe hardware offers significant advantages: Latencies are between 10–100μs (far lower than SATA SSDs/HDDs), and PCIe 4.0 NVMe bandwidth reaches up to 7GB/s—roughly 1/10th of DRAM and far exceeding traditional storage.
Memory tiering minimizes performance impact primarily through application-transparent management, intelligent scheduling, and low-latency NVMe, ensuring the CPU always operates on high-speed paths. Combined with kernel I/O path optimization and the seamless inheritance of NUMA local affinity, overall server memory capacity is doubled while actual performance drops are reliably kept under 10%.
Live Demo: Memory Tiering in Action
Double Server Memory with Only 6% Performance Loss | Sangfor HCI Memory Tiering Tested
- Before Memory Tiering: 256G physical memory, up to 73% utilization. Oracle Database TPS (Transactions Per Second): 15000+.
- After Memory Tiering: 128G physical memory + 128G Tiering Memory, equivalent to 256G memory capacity. Oracle Database TPS average remained stable around 14000, with a performance drop securely controlled within 10%.
Practical Implementation Guide: Applicable Scenarios and Planning Recommendations
Applicable Scenarios
- Ideal Scenarios: Memory tiering is suitable for use cases requiring large total memory capacity, with distinct hot/cold data access patterns, cost sensitivity, and tolerance for slight, occasional latency. Examples include development & testing environments, non-core caching services, and low-to-mid load microservice clusters.
- Not Recommended For: It is not suitable for core applications that are extremely sensitive to access latency, have dense and uniform access patterns, and require strictly low jitter and high stability. Examples include Real-time trading systems, high-frequency trading databases, in-memory databases, and high-frequency OLTP databases.
Sangfor's Memory Tiering solution supports enabling or disabling the feature at the virtual machine (VM) level. Users can flexibly toggle memory tiering for specific VMs based on business type and characteristics, allowing for fine-grained control over both performance and cost. If hardware prices drop in the future, users can seamlessly scale up capacity online without vendor lock-in or future upgrade concerns.
Best Practice for Memory Tiering Planning
To balance memory expansion with business performance stability, the recommended ratio of DRAM to Tiered Memory is 1:1. This ratio covers the needs of most enterprise scenarios, successfully doubling memory capacity while keeping performance fluctuations well within an acceptable range.
In a market environment where memory hardware prices remain high, memory tiering is no longer just a performance optimization tool; it is a highly effective cost-control strategy. Users can dramatically cut memory hardware procurement budgets without sacrificing core business performance, maximizing the reuse value of existing IT assets to calmly tackle the dual challenges of computing power growth and IT cost management.
