Summarize this blog article with AI:
Hardware costs and delivery timelines are becoming increasingly unpredictable. With the rapid commercialization of large-scale AI models, the explosive growth in global computing cluster deployments has significantly consumed the production capacity of core hardware components such as CPUs, memory, and high-speed SSDs. Hardware delivery cycles are now often extended to several months, memory prices have surged sharply, and supply chain volatility has become a long-term variable.
Faced with the dual pressure of limited budgets and the need to launch workloads on schedule, how can IT teams deliver new services without overspending? More importantly, how can infrastructure scale efficiently under these constraints?
During this period of supply chain pressure, Sangfor—as a trusted partner supporting organizations across industries on their digital and intelligent transformation journey—aims to leverage its accumulated expertise in software-defined technologies and technical solutions. Combined with recent discussions with many customers, we have summarized a practical and cost-effective approach to help organizations navigate this challenge: Optimizing existing infrastructure resources.
Optimization Strategy for Existing Third-Party / HCI Users: Maximize Utilization of Legacy Server Resources and Reduce New Resource Investment
Target Users
Organizations with existing server assets (whether running VMware, third-party virtualization platforms, or Sangfor HCI) that are currently facing resource bottlenecks and require expansion, but due to rising hardware prices and tight budgets, hope to launch new workloads within their existing budget.
In many cases, data center resources are not truly exhausted but are instead “idling”. Sangfor aims to help users activate these legacy resources so that budgets can be allocated where they are most needed.
Step 1: Reclaim Unused Resources with AI-Driven Assessment
Unused resources often already exist in most data centers and can be reclaimed without new hardware investment. How can these unused resources be identified? By using AI-driven tools to detect zombie virtual machines and over-provisioned workloads. We provide professional intelligent resource assessment tools and expert services. Through machine learning algorithms, the system can accurately scan and identify long-idle “zombie virtual machines” and over-provisioned workloads within the underlying platform. Through proper resource reallocation and cleanup, a substantial amount of available compute capacity can often be directly released. Based on recent market pricing data:
- Each 1 GB of reclaimed memory can save approximately $35–$42 in procurement costs.
- Each 1 TB of reclaimed storage can save approximately $56–$70.
These previously hidden wasted resources are directly converted into visible benefits, optimizing both resource utilization and cost.
Step 2: Expand Memory Capacity with Tiered Memory Technology
Memory capacity, not CPU, is often the primary bottleneck in modern workloads. In real-world operations, servers are often in a state where “CPU still has headroom, but memory is already fully utilized.” Faced with expensive memory modules, Sangfor introduces DRAM + NVMe SSD memory tiering technology.
Users only need to add a cost-effective NVMe SSD to an existing server as a “secondary memory tier” to directly double the available memory capacity of the host (up to a maximum).
In actual testing:
A server with 128 GB of physical memory, after being equipped with an NVMe SSD, can achieve an effective memory capacity close to 256 GB. When running an Oracle database, TPM (transactions per minute) remains stable at around 2500, with minimal performance impact, while memory capacity is effectively doubled. This demonstrates that memory capacity can be effectively expanded with minimal performance impact.
Before enabling memory tiering:
- Physical memory capacity: 128 GB
- Utilization rate: as high as 77%
- Oracle performance test: database TPM 2700+
After enabling memory tiering:
- Effective memory capacity equivalent to 256 GB
- Oracle performance test: average TPM stabilized at around 2500
- Performance degradation controlled within 10%
This shows that performance remains stable even as effective memory capacity doubles.
Sangfor’s memory tiering technology, through the efficient combination of DRAM and NVMe SSD, significantly reduces hardware procurement costs while meeting total memory requirements.
Under the same hardware configuration and with a memory tiering ratio of 1:1, taking Intel 3rd Generation platforms (DDR4 memory) and Intel 5th Generation platforms (DDR5 memory) as examples, and comparing pure DRAM procurement solutions with DRAM + NVMe SSD combination solutions, the cost savings are as follows:
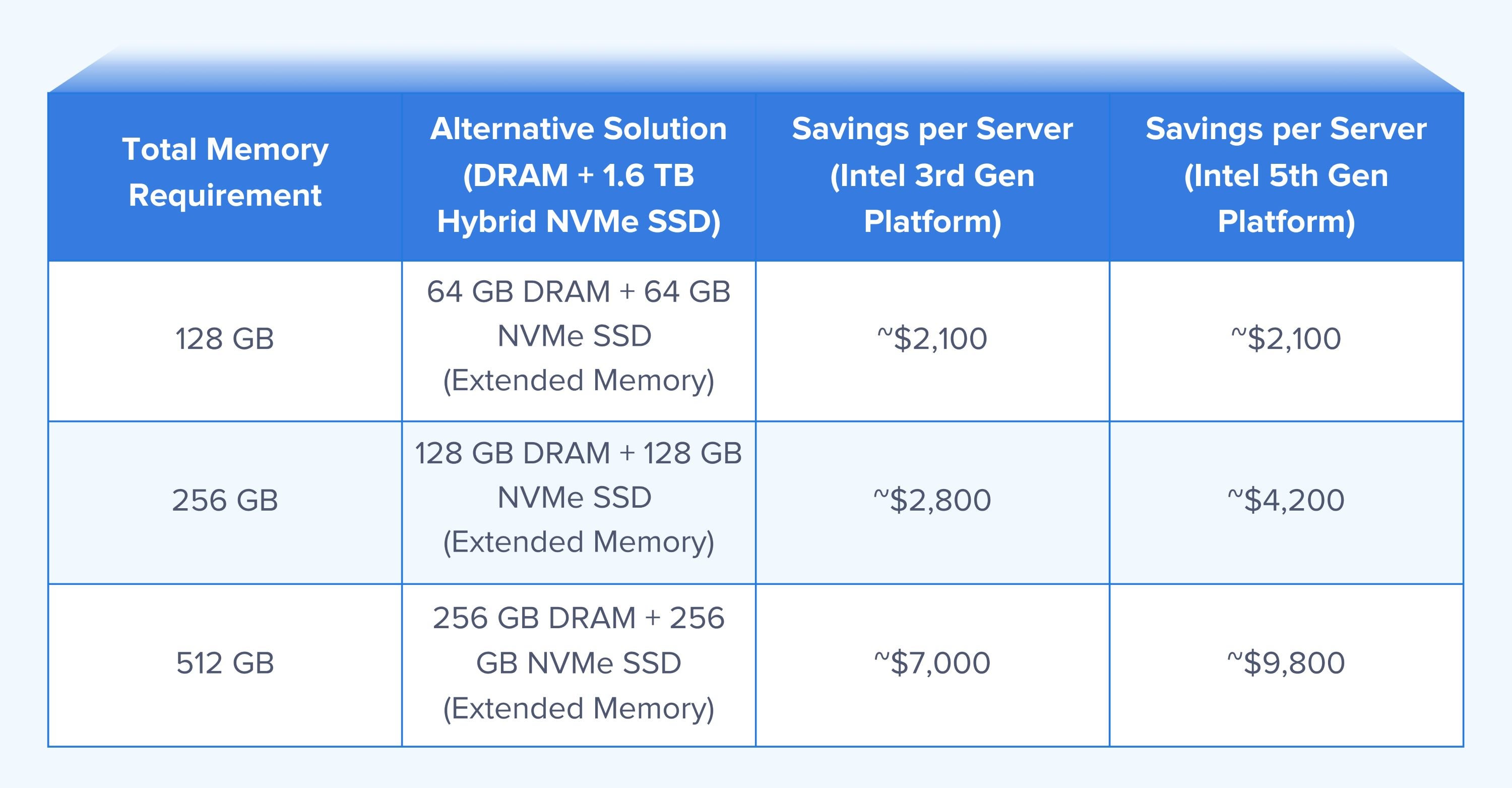
Cost savings increase as memory demand grows. When total memory requirements increase from 128 GB to 512 GB, cost savings per server can reach up to ~$9,800, achieving a balance between memory performance and procurement cost and delivering higher return on investment.
What Technical Capabilities Enable the Doubling of Available Memory?
Intelligent hot and cold data tiering, fully transparent to workloads
The system automatically identifies hot and cold data—cold data is moved to the NVMe-based secondary memory tier, while hot data remains in DRAM. The entire process is fully automated and transparent, with no impact perceived by applications.
Real-time monitoring and intelligent optimization, ensuring uninterrupted operations
The system continuously monitors memory tiering and data swapping status. Once abnormal fluctuations or excessive pressure are detected, optimization strategies are automatically triggered in advance to avoid performance jitter and ensure business continuity.
Optimized memory swapping mechanism, ensuring stability during peak loads
By optimizing kernel scheduling and page migration paths in tiered memory scenarios, the system reduces performance fluctuations caused by frequent data swapping and ensures stable operation even under high workloads.
Software-defined reliability ensures that legacy hardware can still support critical workloads. In addition, Sangfor has built comprehensive software-defined reliability mechanisms at the underlying layer (such as HA 2.0, sub-health detection, and live migration), using software redundancy algorithms to compensate for the physical limitations of legacy hardware. This ensures that revitalized clusters can still stably support core business workloads, allowing legacy equipment to deliver renewed value.
Conclusion
Software-defined infrastructure reduces reliance on unpredictable hardware supply cycles. By optimizing existing infrastructure and extending resource capacity through software-defined technologies, organizations can better withstand supply chain volatility. In an environment where hardware supply remains uncertain, Sangfor continues to use software-defined capabilities to reconstruct resource efficiency—leveraging technological certainty to hedge against external uncertainty.
With an open and compatible ecosystem, Sangfor protects every existing customer investment and provides infrastructure solutions that are truly non-binding, highly reliable, and cost-efficient.
Frequently Asked Questions
Organizations can reduce costs by optimizing underutilized resources, reclaiming idle capacity, and using memory tiering technologies to minimize new hardware purchases.
Memory tiering cannot fully replace DRAM, but it can significantly extend usable memory capacity—often up to 2x—while keeping performance impact within an acceptable range.
By combining resource optimization and memory tiering, organizations can significantly increase usable capacity while avoiding costly hardware upgrades.
