Customer Overview
Global Business Power Corporation (GBP) is a leading energy company (Top-3) in the Philippines, producing high quality, reliable, and cost-efficient power supplies through five subsidiaries and ten power generation facilities nation-wide.
In 2017, GBP decided to refresh its data center infrastructure by searching for a reliable, scalable, redundant, and secure data center environment. Their legacy setup was not meeting the business requirements of hardware redundancy, auto backup, disaster recovery, disaster recovery simulation, and ease-of-management.
Business Pain-Points
Managing multiple sites is complex. In each data center, there are many devices from various vendors. Computing virtualization was from VMware, switch, and router from Cisco, and storage and physical server were from Dell. IT admin were required to simultaneously open many tabs to monitor all devices. Troubleshooting required administrators to physically visit the server room, as all devices ran independently.
GBP’s business system continuity was weak, with no HA in place. During peak hours GBP saw a rise in access requests from end-users and core business systems like IBM Maximo or EDMS, which their legacy system was unable to handle. There was also no failover or accident-triggered mechanism to keep business running in the event of a power outage or accidental disk plug-out. Because DRS functions require an enterprise license, resources could not be expended automatically if a virtual machine encountered an insufficient resource issue.
Data was not well-protected and the amount of time it took to restore application functionality was too long, taking five days to restore application functionality (RTO=5 days). IT admin needed to troubleshoot defective systems remotely the with help of a local IT admin. The amount of data lost during network downtime was far too high. IT admin was forced to copy data from storage to tape each month as a backup, causing many issues. First, tape backup is a lengthy process, as this technology isn’t capable of high-speed writing. Secondly, the tape was incapable of backing up updated data, requiring IT admin to backup all data every month. Thirdly, due to a lack of disaster recovery mechanisms, IT admin was forced to fly to deliver the tapes to various sites every month, so that the plants could load the tapes when necessary. Therefore, RPO was between one week to one month, which proved to be far too long.
Sangfor Solution
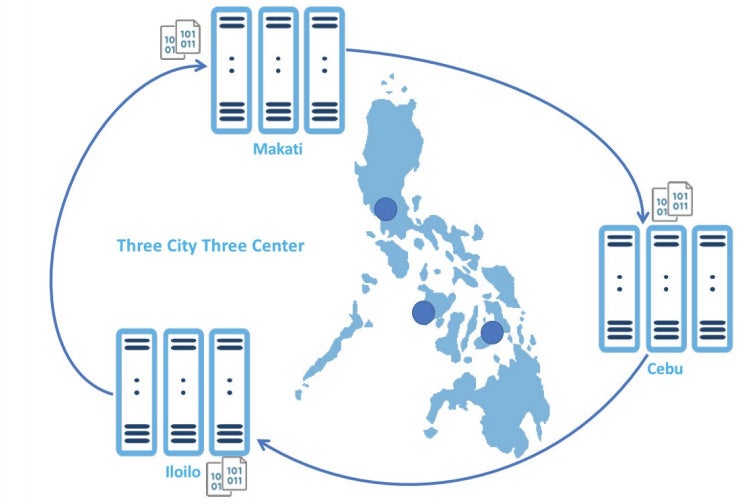
The ideal solution must be stable, easy to manage and use, and able to maintain data integrity. Sangfor provided GBP with a tailor-made solution, far beyond their expectations, to accommodate their needs. GBP kept three data centers in Makati, Cebu, and Iloilo (Makati critical data backed-up in Cebu. Cebu critical data backed-up in Iloilo. Iloilo critical data backed-up in Makati). In each data, center GBP consolidated all virtual machines with Sangfor aCloud and ran them on Sangfor aServer and Dell servers. All business applications run on these three clusters. On the Sangfor aCloud platform, GBP activated many functional licenses. The basic license package includes aSV, aSAN, and aNET. For backing up all data among the three data centers, GBP activated aDR. For managing and monitoring three sites, GBP activated aCMP. For compressing and optimizing data transactions, GBP activated vWANO.
End-User Experience
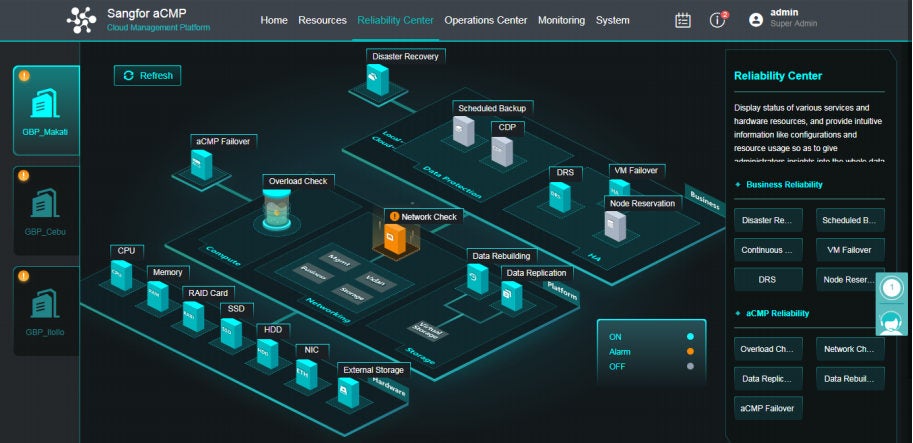
Management and monitoring become easy. aCMP provides a great tool to centrally monitor and manage all Sangfor clusters. With this management web-console, GBP can operate all maintenance and supervision activities on it like creating VM, monitoring status of hardware and aCloud software, percentage of backed up data, the throughput of each site, and status of each VM of all sites (usage of storage, CPU, and memory), etc.

The business now runs continuously without disruption. Because GBP has a cross-site active-standby datacentre when one VM or physical server encounters an accident, traffic is transferred to another city, and business isn’t influenced. Secondly, high availability is enabled on each aCloud cluster. Failover and aMotion are triggered by any disruption or incident like power outrage and disk or cable plug-out. Migration between nodes is instant and automatic. Thirdly, the Sangfor solution included file-level recovery capability to recover files from an image backup. If a VM suffers a ransomware attack, the system is recovered quickly and easily. Critical systems’ stability and reliability have been greatly improved. Fourth, through built-in Dynamic Resource Scheduling (DRS) in Sangfor aCloud, they are now confident that the systems will always have enough resources for end-users.
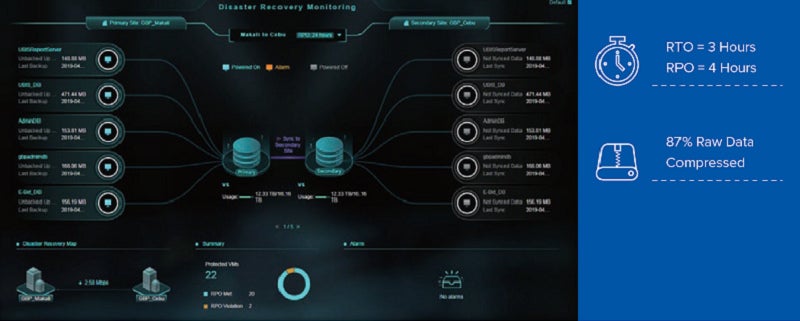
Data is well-protected and RTO/RPO is minimized. Through aCMP and aDR, RTO has been minimized from 1 week to 3 hours and RPO has been minimized from 1 month to 4 hours. The disaster recovery simulation function allows the company to simulate a disaster with a few clicks of a button. The most impressive function is the offsite backup optimization, with limited bandwidth capacity. The Sangfor solution ensured that GBP can transfer backup data offsite with at least an 87% compression rate. Finally, while GBP generates 136G of raw data daily, the vWANO and aCloud compression feature mean that post-compressed data is only 17.68G.