Summarize this blog article with AI:
Introduction
As organizations accelerate their VMware replacement initiatives, one question consistently surfaces: Will my database and I/O-intensive workloads perform as well—or better—on the new virtualization platform? For years, VMware vSphere has been the gold standard for running mission-critical applications, and any migration naturally raises concerns about performance consistency, latency spikes, and resource efficiency.
Sangfor Virtualization (HCI) is not merely a drop-in replacement. It is engineered to address the most demanding performance requirements of core business systems. By deeply optimizing the underlying architecture, particularly around Non-Uniform Memory Access (NUMA) scheduling and memory capacity expansion, Sangfor Virtualization ensures that databases, in-memory caches, and other I/O-sensitive workloads not only maintain but often exceed their previous performance levels.
In this post, we will dissect two critical technologies that make this possible: Adaptive NUMA Scheduling and Memory Tiering. Drawing on validated test data and architectural insights, we will explore how these features tackle the fundamental performance bottlenecks in modern server environments.
Part 1: Conquering Memory Access Latency with Adaptive NUMA Scheduling
The NUMA Challenge in Virtualized Environments
Modern enterprise servers rely on NUMA architecture to scale beyond the limitations of traditional symmetric multiprocessing (SMP). In a NUMA system, the processor cores and memory are divided into nodes. Each node has its own local memory, and while accessing local memory is fast, accessing memory from a remote node incurs significant latency. Local memory accesses take ~70–90 ns; remote accesses are usually 1.5–2× slower and can degrade further with contention.
In a virtualized environment, each virtual machine (VM) is represented as a set of vCPU threads. If these threads are scheduled across different NUMA nodes, or if they migrate between nodes, the VM will experience remote memory accesses, leading to unpredictable latency and reduced throughput. This is particularly detrimental to database systems like Oracle, DM8, and PostgreSQL, as well as in-memory data stores like Redis.
VMware vSphere's Approach: vSphere 6.0 and later versions include an automatic NUMA scheduler that handles most general workloads effectively. It provides features like vNUMA exposure and load balancing across nodes. However, for highly specialized I/O-intensive workloads, administrators may still need to fine-tune CPU affinity settings or adjust advanced parameters to achieve optimal performance.
Sangfor Virtualization‘s Adaptive NUMA Scheduling
Sangfor Virtualization takes a fundamentally different approach. Instead of relying on manual intervention, it implements a fully adaptive NUMA scheduling engine that operates automatically and dynamically. The scheduler continuously analyzes the vCPU count of each VM and the real-time load of physical NUMA nodes, then makes optimal placement decisions. As illustrated in the figure, the system automatically selects the appropriate NUMA node for each virtual machine. When the vCPU count of a VM is less than the number of cores on a NUMA node, the VM is scheduled onto a single NUMA node. When the vCPU count exceeds the number of cores on a NUMA node, the VM is scheduled across multiple NUMA nodes, and the vNUMA topology is exposed to the guest OS, enabling the VM to make optimal decisions internally.
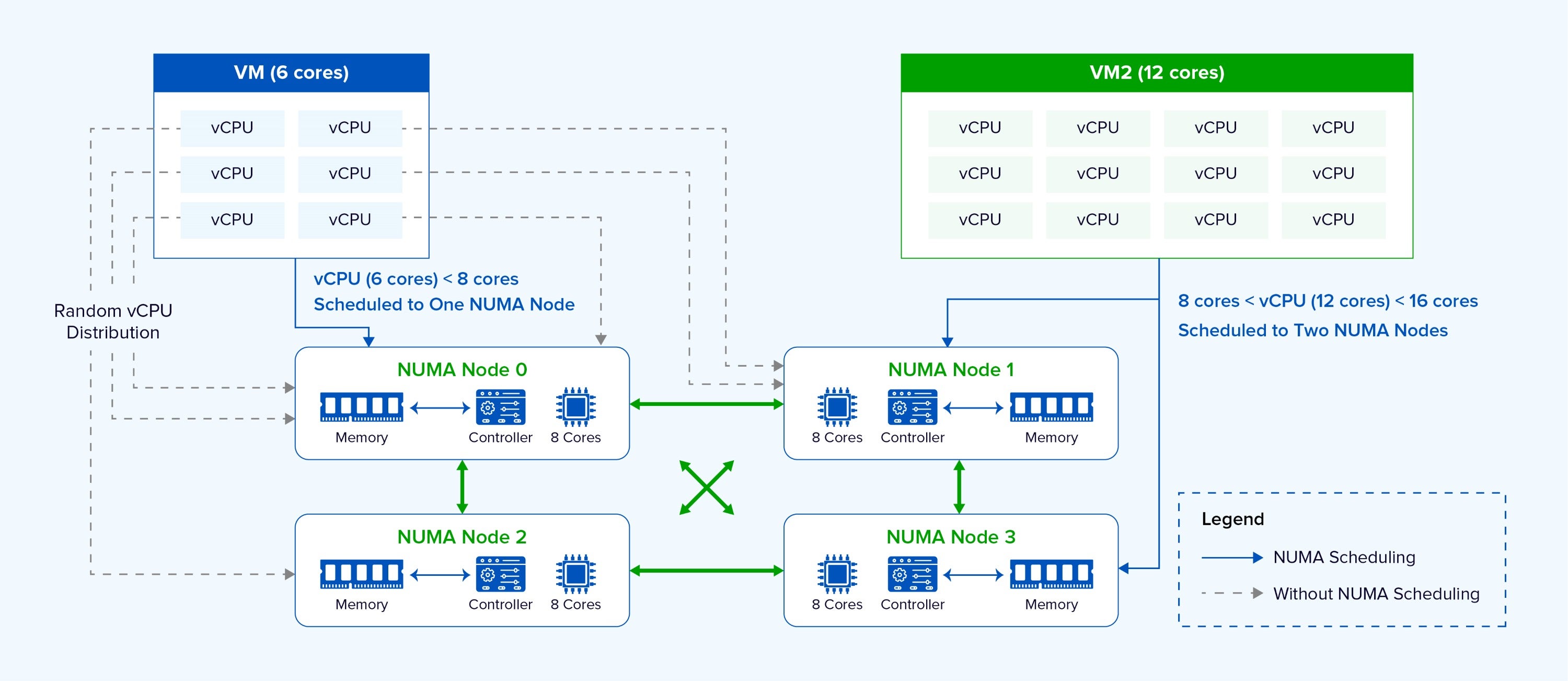
- vCPU Consolidation: When a VM’s vCPU count is less than or equal to the number of cores on a single physical NUMA node, Sangfor Virtualization places all its vCPUs and memory within that same node. This ensures 100% local memory access for that VM, eliminating cross-node latency.
- Intelligent Spreading for Large VMs: For VMs with more vCPUs than a single node can accommodate, the scheduler distributes them across multiple NUMA nodes. Crucially, it also exposes the virtual NUMA (vNUMA) topology to the guest OS. This allows the operating system inside the VM to make informed scheduling decisions, further optimizing memory locality.
- Load Balancing Across Nodes: The scheduler monitors NUMA node loads and can migrate VMs between nodes when necessary to prevent resource contention. It also identifies “important” VMs (such as those running critical databases) and prioritizes their placement on less-contended nodes to ensure stable performance.
Beyond vCPU: Storage and Network NUMA Affinity
What sets Sangfor Virtualization apart is that its NUMA optimizations extend far beyond CPU scheduling. A complete I/O path—from the vCPU, to the QEMU process, to the aSAN storage service, and even to the network data forwarding process—can be intelligently pinned to the same NUMA node. This holistic approach eliminates remote memory access across the entire I/O stack, drastically reducing processing overhead.
Combined with large memory pages (huge pages), this optimization directly benefits database and storage-intensive applications. For example, when a database performs a write operation, the entire workflow stays within the same NUMA domain, minimizing latency and maximizing throughput.
Note: NUMA affinity optimization applies within each individual host. Cross-host storage access in distributed configurations (such as aSAN) will still incur network latency as expected in any distributed architecture.
Performance Validation
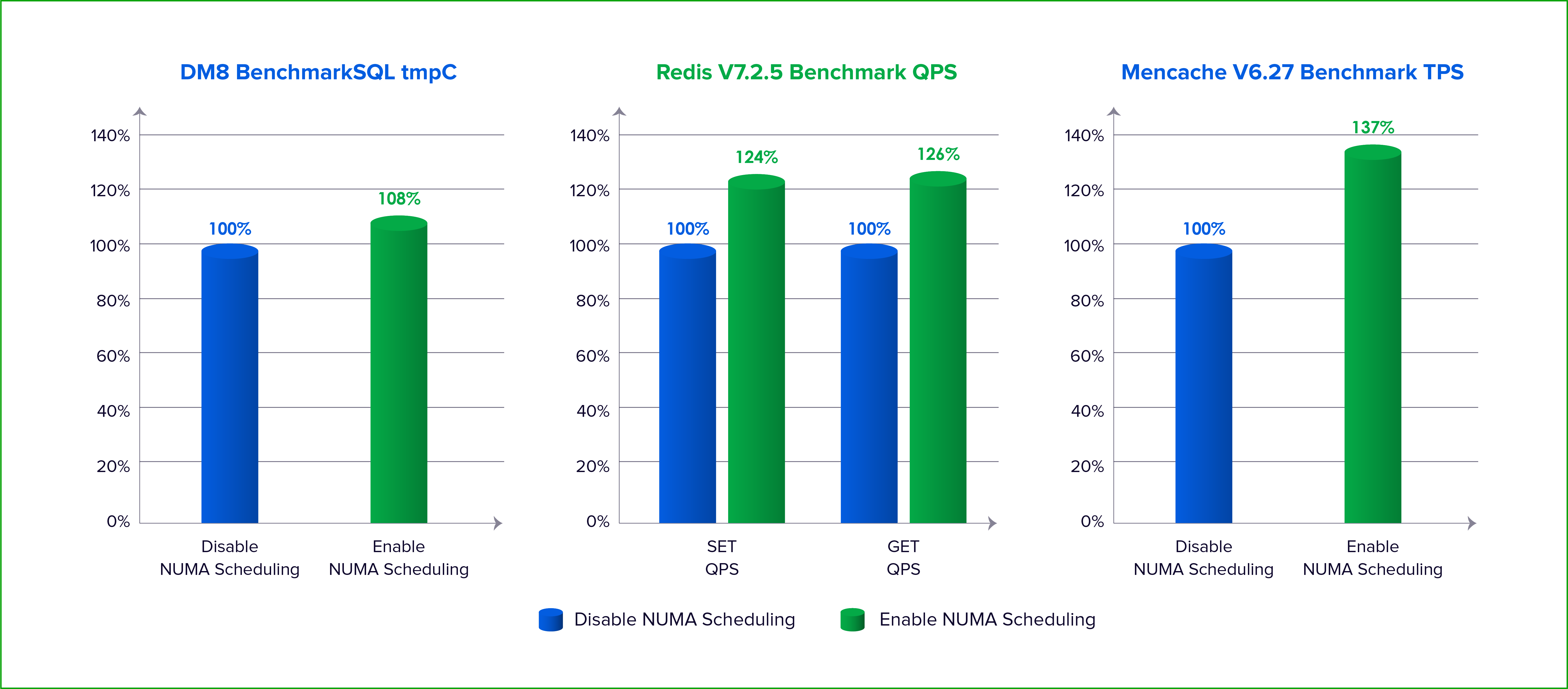
The effectiveness of these optimizations is validated through rigorous testing. In one benchmark using DM8 (a leading domestic database) and the standard BenchmarkSQL tool (TPC-C model), enabling Sangfor Virtualization’s NUMA scheduling resulted in a substantial increase in tpmC compared to a configuration where NUMA scheduling was disabled.
Similarly, in Redis benchmarks using redis-benchmark for SET/GET operations, the queries per second (QPS) improved markedly when NUMA scheduling was active. Memcache tests using memaslap also showed higher transactions per second (TPS). These results demonstrate that for memory-access-sensitive workloads—precisely the applications most likely to be impacted by poor NUMA configuration—Sangfor Virtualization delivers tangible performance gains.
Part 2: Breaking the Memory Capacity Barrier with Memory Tiering
The Memory Cost Dilemma
For databases and I/O-intensive applications, memory capacity is often the single most critical resource. Larger memory pools enable bigger buffer caches (such as Oracle SGA), higher in-memory data processing, and increased concurrency. However, DRAM prices remain volatile, and hardware supply chain constraints can make large-scale memory upgrades prohibitively expensive.
Traditional techniques used in platforms like VMware vSphere—including memory compression, transparent page sharing, and memory overcommit—can improve utilization but have inherent limitations. They do not fundamentally increase the amount of memory available to the system; they merely make existing DRAM more efficient. When workloads demand more active memory than physically available, performance inevitably degrades.
How Sangfor Virtualization Memory Tiering Works
Sangfor Virtualization introduces a paradigm shift through Memory Tiering. This technology creates a unified memory pool by combining fast DRAM with high-performance NVMe SSDs. The core idea is to use the NVMe SSD as an extension of system memory, effectively doubling the available capacity without adding DRAM.
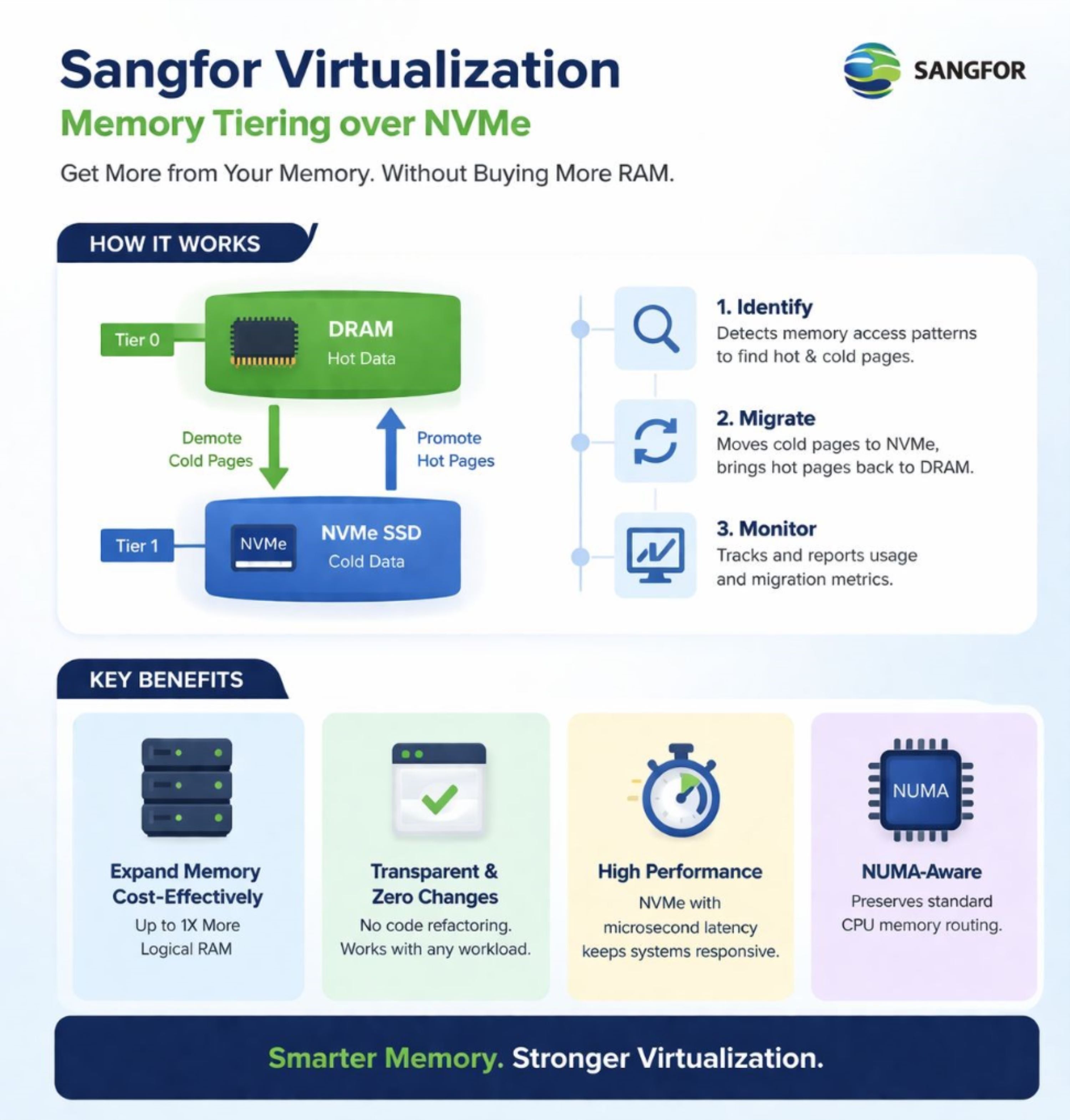
The magic lies in intelligent data placement. Using a lightweight dynamic region partitioning and random sparse sampling mechanism, Sangfor Virtualization continuously monitors memory pages to distinguish between “hot” (frequently accessed) and “cold” (infrequently accessed) data.
- Hot data—such as active database indexes, critical transaction logs, or frequently queried tables—remains in the DRAM tier (Tier 0) for low-latency access.
- Cold data—such as historical records, backup-related pages, or idle application memory—is automatically moved to the NVMe tier (Tier 1). This migration is performed transparently, without any involvement from the guest OS or application.
CPU Access Flow and Performance Control
When a CPU requests a memory address, the system checks the DRAM tier. If the page is found (hot hit), access is immediate. If it is not present (cold miss), the system triggers a transparent page fault, quickly moves the required page from NVMe back to DRAM, and then completes the CPU access. From the application’s perspective, the process is indistinguishable from a standard memory operation.
Critically, the NVMe tier is treated as memory, not as a swap device. The NVMe controller leverages PCIe bandwidth to move data with minimal CPU intervention. With modern PCIe 4.0/5.0 NVMe drives delivering latency in the range of 10–100µs and bandwidth up to 7 GB/s, the overhead of cold-page promotion is kept extremely low.

In real-world Oracle database tests, enabling memory tiering allowed a server with 128 GB of physical DRAM to effectively support a workload that would normally require 256 GB. The resulting TPM (transactions per minute) decreased by only about 10%, a modest trade-off for doubling the usable memory capacity.
Deployment Flexibility and Best Practices
Not all workloads are ideal candidates for memory tiering. It is best suited for scenarios with distinct hot/cold data patterns, such as:
- Desktop virtualization (VDI)
- Development and test environments
- Non-critical caching services
- Moderate microservice clusters
For ultra-low-latency requirements, memory tiering can be selectively disabled on a per-VM basis:
- High-frequency trading systems
- Latency-sensitive OLTP databases with uniform access patterns
- Real-time analytics with strict SLA requirements
Sangfor recommends a DRAM-to-tiering capacity ratio of 1:1 to achieve optimal balance—delivering double the effective memory with minimal performance impact.
Conclusion
Migrating from VMware vSphere to Sangfor Virtualization is not merely a lateral move; it is an opportunity to re-architect your virtualization layer for higher performance and greater efficiency. For database and I/O-intensive workloads, the two technologies discussed—Adaptive NUMA Scheduling and Memory Tiering—directly address the most critical constraints of modern infrastructure: memory access latency and memory capacity.
Adaptive NUMA Scheduling ensures that your databases, in-memory caches, and middleware run with predictable, low-latency access to local memory, automatically adapting to workload dynamics without the need for manual intervention. Memory Tiering, on the other hand, offers a pragmatic path to scaling memory capacity without the prohibitive cost of DRAM, enabling you to consolidate more workloads per server while maintaining performance within acceptable bounds.
With these innovations, Sangfor Virtualization delivers a platform that not only matches the performance expectations set by VMware vSphere but often exceeds them—especially in the demanding scenarios that define modern core business systems. As you navigate your VMware replacement journey, rest assured that your most critical applications are in capable hands.
If your organization is navigating similar challenges, we invite you to contact us. We are ready to conduct a collaborative assessment and develop a bespoke transition plan that aligns precisely with your environment.
